非公式MySQL 8.0オプティマイザガイド
変わりゆく実行計画(Transient Plans)
原文URL: http://www.unofficialmysqlguide.com/transient-plans.html翻訳者: taka-h (@takaidohigasi)
同じようにみえるクエリーも全く違った実行計画となることがあります。これまでpopulationの述部を修正することによって確認してきました。例8では、population > 500M(5億)を指定することで population >5M(500万)を指定した場合と異なったインデックスが選択されました。
クエリーの一部がユーザー入力から生成される本番環境では、このようなことはとても良く発生します1。例としては、
- 数カ月分のデータに対して「昨日から現在まで」の範囲の日付を指定した場合、おそらく日付の列のインデックスが利用されることでしょう。一方で「昨年から現在まで」を指定した場合はインデックスは利用されないかもしれません。
- WHERE
is_deleted=1のレコードを探すには、多くのレコードが除外され、したがってインデックスにとても適しています。同様にWHEREis_deleted=0はインデックスには適さないでしょう。
これは予期された挙動で、統計収集(「メタデータと統計」の章で言及済み)の結果です。次の表は、populationとcontinent が変わった際にインデックスの相対的コストがどの程度変化するかを示しています。
| p>5M,c=’Asia’ | p>5M,c=’Antarctica’ | p>50M, c=’Asia’ | p>50M,c=’Antarctica’ | p>500M, c=’Asia’ | p>500M,c=’Antarctica’ | |
|---|---|---|---|---|---|---|
| p | 152.21 | 152.21 | 34.61 | 34.61 | 3.81 | 3.81 |
| c | 28.20 | 6.00 | 28.20 | 6.00 | 28.20 | 6.00 |
| c,p | 24.83 | 2.41 | 16.41 | 2.41 | 3.81 | 2.41 |
| p,c | 152.21 | 152.21 | 34.61 | 34.61 | 3.81 | 3.81 |
| テーブルスキャン | 53.80 | 53.80 | 53.80 | 53.80 | 53.80 | 53.80 |
- テーブルスキャンは常にテーブル内の各行を探索するため、比較的固定されたコストとなります
pまたはcのインデックスを利用するときのコストは、入力値で効率的にフィルター出来るようになるにつれて変化します(Antarctica: 南極大陸には国の数が少なく、人口が多くなればなるほど対象となる国の数は少なくなります)c, pへの複合インデックスはほとんどのクエリーに対して比較的効率的にコストを削減できています。pへのインデックスに対するコストと、p,cの複合インデックスに対するコストは既に説明済みの理由によって同一となります。p,cインデックスは”範囲が左側”にあるためpのインデックスしか利用されません。- このデータセットでは、南極大陸には人口0の4つの国があります。
c,pへの複合インデックスに対するクエリーが一番低コストなクエリーとなり、これは結果セットが0件であるためです。
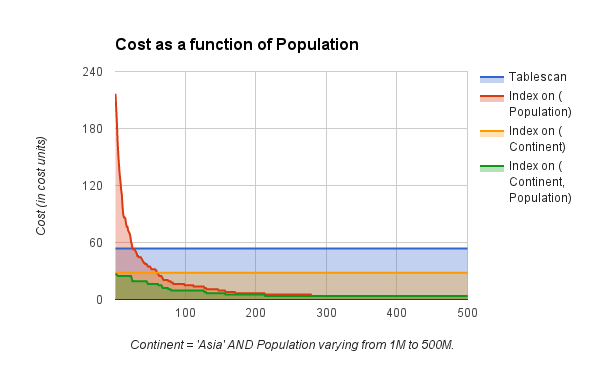
これは視覚的にも表すことが出来ます。continentへのテーブルスキャンおよびrefアクセスは一定コストであり、(Continent, Population)への複合インデックスがcontinentへのrefアクセスと同一コストで始まり、このときpopulationの選択性は高くありません。populationが大きくなるに連れて選択性が増します。
複合インデックスが効果的でなければ、個々のインデックス(pupulationまたはcontinent)と近いコストになるでしょう。最後にpopulation > 3M(300万)の国はすべてアジアにあるため、選択性はpopulationへのインデックスを利用したときとほとんど変わりません。
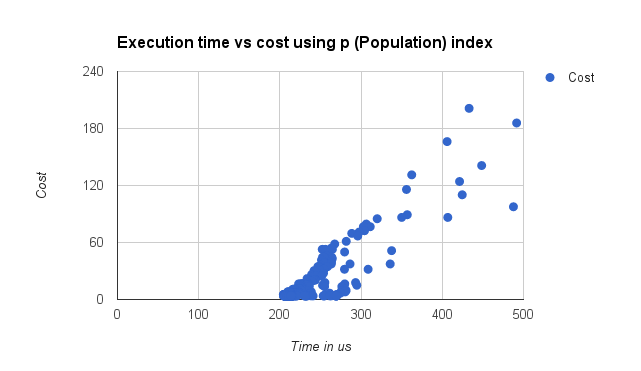
次の可視化はインデックスpを強制的に利用させ、populationを(WHERE population > 1M(100万)からWHERE population > 500M(5億)まで)変えて100回実行した際の実行時間の中央値を示しています。実行時間はperformance_schema.events_statements_history_longから取得し、マイクロ秒(μs)に変換しています。データセットが小規模で、人口が少ない国がとても少ないため、同一のページがアクセスされたと思われる実行時間のクラスターがみられるのではないかと思います。
しかしながらいくらかの相関がみられます。
-
クエリーの分布によっては、これらの例の両方のケースでインデックスを生成するより、パーティショニングした方がうまく動作するかもしれません。 ↩