非公式MySQL 8.0オプティマイザガイド
B+ツリー インデックス
原文URL: http://www.unofficialmysqlguide.com/btrees.html翻訳者: taka-h (@takaidohigasi)
「インデックスを追加する」といったら、それが主キーであれ、ユニークキーであれ、あるいはそうでなかったとしても、通常は「B+ツリーインデックスの追加」となります(他のインデックス種別も利用できます)。B+ツリーをよく理解することで、個々のクエリーのパフォーマンスを向上させられるだけでなく、メモリー上に必要なデータ量(ワーキングセット)を削減できます。これは結果的にデータベースの「全体的なスケーラビリティー」を向上させるのに役立ちます。
B+ツリーの仕組みを説明するのに、Bツリーの仕組みの説明から始め、それから両者は何が違うのかを説明したいと思います。
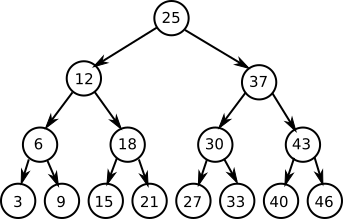
Bツリーの主な特性は「二分探索」にあります。つまり、「100万」の(平衡)Bツリーから829813を探すときに最大でも20ホップで見つけられるのです。これは100万のリストをスキャンすることと比べると非常に大きな進歩です。
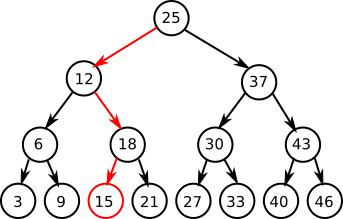
20ホップがそのまま20回のディスクアクセスを発生させる場合、少ない回数とはいえなくなり、この点からBツリーは性能上劣っています。小規模な複数のIOアクセスは比較的高コスト1なのです。これに比べ、同じ検索をB+ツリー2でおこなうとわずか2ホップでよくなります。
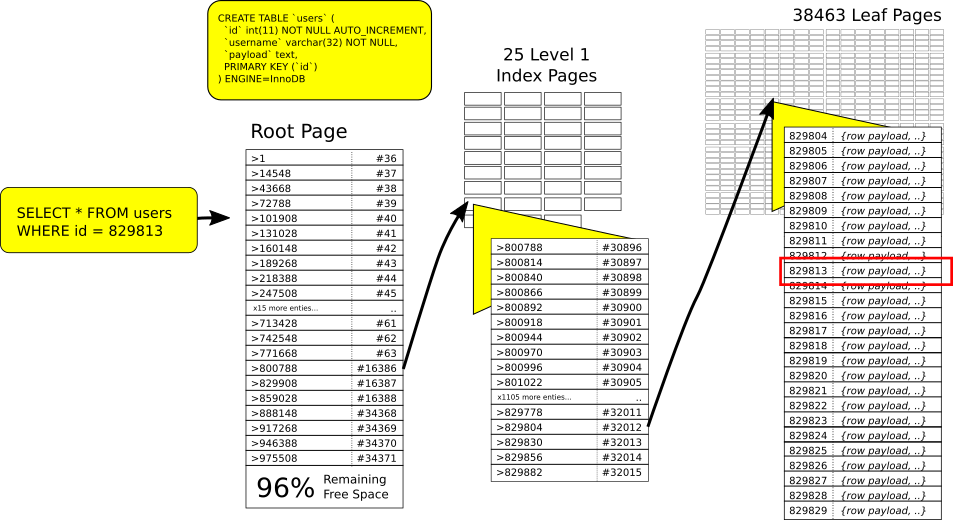
上記の図ではルートインデックスページは25のインデックスページへのポインタを保持しており、このインデックスページ自体は平均で1538のリーフページヘのポインタをもっていることを示しています。829813への経路は図上でハイライトされておりこれは次のとおりです。
- ルートページにて: 値は800788以上、829908より小さいので16386のページへ
- ページ16386にて: 値は829804以上、829830より小さいのでリーフページ32012へ
つまり、B+ツリーはBツリーに比べて2点拡張されているわけです。
- ページに至るまでのデータの組織化 : これはストレージからデータを読み書きするときの基本単位です。データベース用語としての「組織化」はクラスタリングとも呼ばれます(データベースクラスターとは異なります)
- ツリー自体が広く、そして深くない : それぞれのインデックスページに1000強のキーを保存でき、これらが1000のキーをもつインデックスページのポインタをもてば、B+ツリーでリーフページ(ここの主キーに対して全ての行データをもつ)に達するまでに3ホップ以上必要なケースはあまりないでしょう。B+ツリーはBツリーに比べ遥かに高速に広がるためこのようになります。
ルートページ、および25の内部インデックスページを加えても400KiBのメモリーしか必要としません(各ページはそれぞれ16KiB)。38463個のリーフページは600MiBの容量を必要としますが全てが同時にメモリ上にある必要があるわけではありません。大多数のデータセットは一部が「ホットな」ページで他のページは操作されません。内部的にInnoDBはページアクセスをLRUアルゴリズムのバリエーション3を利用して追跡し、空きを作る必要が発生すればアクセス頻度の低いページをメモリ上から追い出します。
一般的には、データベースの総データサイズをRAMよりはるかに大きくすることができます。我々は、メモリー上に保持しなければならないデータのことを「ワーキングセット」と呼んでいます。ワーキングセットの要件はデータセット毎に異なり、データベース管理者のゴールはこれを減らすことのできる最適化を見つけ出すこととなります。
ほとんどの場合で、300GBのワーキングセットを必要とする500GBのデータベースは、100GBのワーキングセットを必要とする1TBのデータベースより、はるかに最適化が難しくなります。