非公式MySQL 8.0オプティマイザガイド
複合インデックス
原文URL: http://www.unofficialmysqlguide.com/composite-indexes.html翻訳者: taka-h (@takaidohigasi)
アジア大陸のすべての国の人口が500万より多いわけではありませんので、2つの述部を合わせると「作業量を減らす」インデックスとなるはずです。つまり、このデータセットでは複合インデックスによって選択性が改善するわけです。
複合インデックスとしては2つの選択肢が考えられます。
p_c(Population, Continent)にインデックスを追加c_p(Continent, Population)にインデックスを追加
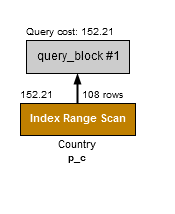
複合インデックスにおける順序の違いは「非常に」重要です。population(人口)はある範囲ですので、オプティマイザはp_c(population, continent)インデックスの最初の部分1 だけが利用できます。p_c(polulation, continent)はp(population)インデックスのみを利用したときと比べてほとんど改善しないわけです。インデックスを強制的に利用するようにすると、これが明確にわかります。
例10: (population, continent)への複合インデックスは良い選択肢ではない
ALTER TABLE Country ADD INDEX p_c (Population, Continent);
EXPLAIN FORMAT=JSON
SELECT * FROM Country FORCE INDEX (p_c) WHERE continent='Asia' and population > 5000000;
{
"query_block": {
"select_id": 1,
"cost_info": { # インデックスの利用が強制されている
"query_cost": "152.21" # テーブルスキャンより高コスト
},
"table": {
"table_name": "Country",
"access_type": "range",
"possible_keys": [
"p_c"
],
"key": "p_c",
"used_key_parts": [ # population列のみ
"Population" # 利用されている
],
"key_length": "4", # populationは4バイトの整数値
"rows_examined_per_scan": 108,
"rows_produced_per_join": 15,
"filtered": "14.29",
"index_condition": "((`world`.`Country`.`Continent` = 'Asia') and (`world`.`Country`.`Population` > 5000000))",
"cost_info": {
"read_cost": "149.12",
"eval_cost": "3.09",
"prefix_cost": "152.21",
"data_read_per_join": "3K"
},
"used_columns": [
"Code",
"Name",
"Continent",
"Region",
"SurfaceArea",
"IndepYear",
"Population",
"LifeExpectancy",
"GNP",
"GNPOld",
"LocalName",
"GovernmentForm",
"HeadOfState",
"Capital",
"Code2"
]
}
}
}
この制約はB+ツリーのインデックス構造によるものです。これを簡潔に覚えるには複合インデックスでは「範囲は右側へ」ということになります。これを考慮して、c_p(continent, population)へのインデックスについて例11で示されています。continentのみのインデックスと比べて、2つの列の組み合わせに対してインデックスを利用することで選択性が改善されて、コストは28.20(例7)から下がっています。2つの列がインデックスで効率的に結合されているため、アクセス方法として「range」が選択されています。
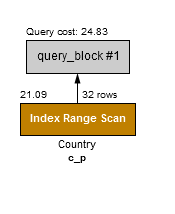
例11: continent, populationへのより適切な複合インデックス
ALTER TABLE Country ADD INDEX c_p (Continent, Population);
EXPLAIN FORMAT=JSON
SELECT * FROM Country WHERE continent='Asia' and population > 5000000;
{
"query_block": {
"select_id": 1,
"cost_info": {
"query_cost": "24.83" # 複合インデックスp,cのコスト(152.21)より
}, # はるかに低コスト
"table": {
"table_name": "Country",
"access_type": "range",
"possible_keys": [
"p",
"c",
"p_c",
"c_p"
],
"key": "c_p",
"used_key_parts": [ # 両方の列が利用されている
"Continent", # 1バイト(ENUM)
"Population" # 4バイト(INT)
],
"key_length": "5", # =5B
"rows_examined_per_scan": 32,
"rows_produced_per_join": 15,
"filtered": "100.00",
"index_condition": "((`world`.`Country`.`Continent` = 'Asia') and (`world`.`Country`.`Population` > 5000000))",
"cost_info": {
"read_cost": "18.00",
"eval_cost": "3.09",
"prefix_cost": "24.83",
"data_read_per_join": "3K"
},
"used_columns": [
"Code",
"Name",
"Continent",
"Region",
"SurfaceArea",
"IndepYear",
"Population",
"LifeExpectancy",
"GNP",
"GNPOld",
"LocalName",
"GovernmentForm",
"HeadOfState",
"Capital",
"Code2"
]
}
}
}
複合インデックスの列順を決める
複合インデックス内の列の正しい順序を決める際には注意が必要です。ここに注意すべき考慮点をいくつか示します。
- 左が最重要 :
(First Name, Last Name)へのインデックスは、(First Name)へのインデックスを必要とするクエリーにも利用できますが、(Last Name)へのインデックスを必要とするクエリーには利用できません。一番多くのクエリで再利用できるように複合インデックスを設計しましょう。 - 範囲は右へ :
(Age, First Name)へのインデックスは、WHERE age BETWEEN x and y AND first_name = 'John'2というクエリーに対して活用できません。もっと具体的にいうと、最初の範囲の条件のあとの残りの複合インデックスは利用されません。 - 選択性の高い列を左へ : インデックスが低コストになり出来る限り高速となるよう考えてみてください。アクセスされるインデックスページ数が少なくなるため、通常はメモリーをよりうまく使えるようになります。
- インデックスの順序(order)の変更に注意 : ASCあるいはDESCを混合すると、複合インデックスがいくつ利用されるかに影響が発生する可能性があります。