非公式MySQL 8.0オプティマイザガイド
はじめに
原文URL: http://www.unofficialmysqlguide.com/introduction.html翻訳者: taka-h (@takaidohigasi)
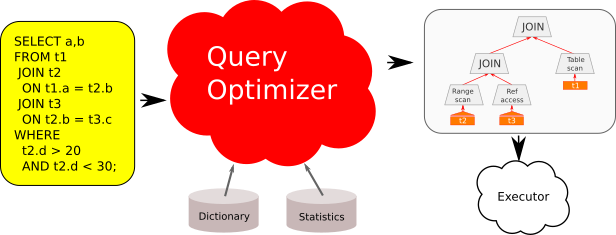
クエリーオプティマイザはクエリーを「入力」とみなし、この章に記述したプロセスを経て実行計画を「出力」として生成します。私はよく、クエリー最適化をGPSのナビゲーションと対比して例えます。
1. 目的地として住所を入力します
- メインストリート 3294番
2. どのように進むと一番効率的に目的地にたどり着けるかを、教えてくれます
- 2マイル直進
- マーカムストリート(Markham Street)で左折
- 500フィート直進
- 右折
- 1000フィート直進
- 右側に目的地あり
住所は目的地です。どのように行くかを指定しなくても、ナビゲーションシステムが考えうる経路について評価し、一番効率的に目的地に到着する経路をアドバイスしてくれることでしょう。
SQL言語は「宣言的」であるという点で、住所とにています。どのようにするかという過程ではなく、最終的な状態を指定します。データベースシステムには、多くのインデックス(そして多くのテーブルとの結合)があるため、ナビゲーションシステムと同じように、同じ結果をえられる多くの方法があります。
このアナロジーのしめくくりとして、GPSのナビゲーションが「常に絶対に一番速い道を案内してくれる」わけではないのと同じことが、クエリー最適化についてもいえます。全ての道に交通量のデータがあるとは限らないのと同様に、オプティマイザも不完全なモデルに対して処理をする必要があります。熟練した方にとっては、チューニングする必要が生じる状況が発生しえるわけです。