非公式MySQL 8.0オプティマイザガイド
コストベース最適化
原文URL: http://www.unofficialmysqlguide.com/cost-based-optimization.html翻訳者: taka-h (@takaidohigasi)
オプティマイザはコストベース最適化と呼ばれる方法に基づいて、クエリーをどのように実行するかを決定しています。このプロセスを単純化すると次のようになります。
- それぞれの操作にコストを割り当てる
- 可能性のあるそれぞれの計画にいくつの操作があるかを見積もる
- 値を合計する
- 全体のコストが一番低い計画を選択する
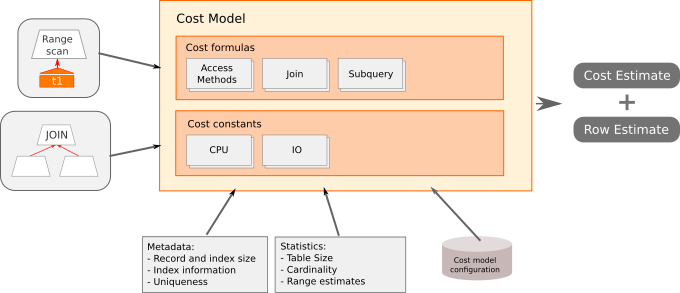
上記が単純化であると述べたのは、オプティマイザは可能性のあるそれぞれの実行計画を徹底的に検索するわけではないからです。例えば、5つのテーブルが結合される場合、各テーブルに5つのインデックスがあるとすると、5! * 5! =14400 を「超える」クエリーの実行パターンがあることになります。
- 各インデックスは1つ以上アクセス方法があります(例えば、インデックススキャン、範囲スキャンやインデックスルックアップです)。その上、各テーブルがテーブルスキャンを利用する可能性もあります。
INNER JOINクエリーではテーブルはどの順序でも結合可能です(テーブルが指定された順序は関係ありません)- 結合する際に、複数の結合バッファーの方法あるいはサブクエリーの戦略が利用可能となります。
オプティマイザが考えうる実行計画を全て評価するのは現実的に実行可能ではありません。例えば、最適化が実行より長い時間かかってしまう場合があるでしょう。このような理由からオプティマイザは、ある一定の計画の評価をデフォルトでスキップします1。クエリー計画を検索する深さを制限するためのoptimizer_search_depthという設定パラメータもありますが、デフォルトでは有効化されていません2。
コスト係数を修正する
それぞれの操作に使われるコストはmysqlシステムデータベース内のserver_costおよびengine_costテーブルを利用して設定可能です。MySQL 8.0でのデフォルト値は次の通りです。
| コスト | 操作 |
|---|---|
| 40 | disk_temptable_create_cost |
| 1 | disk_temptable_row_cost |
| 2 | memory_temptable_create_cost |
| 0.2 | memory_temptable_row_cost |
| 0.1 | key_compare_cost |
| 0.2 | row_evaluate_cost |
| 1 | io_block_read_cost |
| 1 | memory_block_read_cost |
コスト自体はリソース利用量を表す論理的な単位です。1単位にもはや正確な意味はありませんが、起源としては1990年代のハードディスクの1回のランダムIOと遡れます。
ハードウェアが進化したため、全ての構成要素でコストは一定とはみなせません(たとえばストレージのレイテンシーはSSDの出現と共に改善しました)。同様に、ソフトウェアもハードウェアの変化に対してとりくんでいるため(例えば、圧縮のような機能により)、リソース利用量も変化しうるでしょう。コンフィグ可能なコスト係数があれば、このようなケースに対して改善できます。
例4はrow_evaluate_costを5倍にしたため、テーブルスキャンのコストが(インデックスを利用することによってかかる余分なコストと比べて)とても大きくなっていることを示しています。これによってオプティマイザは例2で作成したp(population)インデックスを選択しています。
例4: 行あたりの見積もりが増えることでテーブルスキャンが高コストになる
# コストは0.2から1.0に増える
UPDATE mysql.server_cost SET cost_value=1 WHERE cost_name='row_evaluate_cost';
FLUSH OPTIMIZER_COSTS;
# 新規セッションにて
EXPLAIN FORMAT=JSON
SELECT * FROM Country WHERE continent='Asia' and population > 5000000;
{
"select_id": 1,
"cost_info": { # 行あたりの見積もりが5倍になったため
"query_cost": "325.01" # クエリーに対する合計コストが
}, # 増加します
"table": {
"table_name": "Country",
"access_type": "range", # rangeアクセスで実行されます
"possible_keys": [
"p"
],
"key": "p",
"used_key_parts": [
"Population"
],
"key_length": "4",
"rows_examined_per_scan": 108,
"rows_produced_per_join": 15,
"filtered": "14.29",
"index_condition": "(`world`.`Country`.`Population` > 5000000)",
"cost_info": {
"read_cost": "309.58",
"eval_cost": "15.43",
"prefix_cost": "325.01",
"data_read_per_join": "3K"
},
"used_columns": [
"Code",
"Name",
"Continent",
"Region",
"SurfaceArea",
"IndepYear",
"Population",
"LifeExpectancy",
"GNP",
"GNPOld",
"LocalName",
"GovernmentForm",
"HeadOfState",
"Capital",
"Code2"
],
"attached_condition": "(`world`.`Country`.`Continent` = 'Asia')"
}
}
}
UPDATE mysql.server_cost SET cost_value=NULL WHERE cost_name='row_evaluate_cost';
FLUSH OPTIMIZER_COSTS;# セッションを閉じる
メタデータと統計
例3で示されたように、データの分布は実行計画のコストに影響を与えます。オプティマイザは意思決定プロセスの一部でデータディクショナリと統計を利用します。
メタデータ
| インデックス情報 | ユニーク性 | Nullability | |
|---|---|---|---|
| 概要 | ディクショナリはテーブル毎にインデックスの一覧の情報を持ちます | インデックスがユニークの場合、永久変換に利用され、実行計画のある部分を短縮するのに利用されます | オプティマイザはnullの可能性がある値を正しく扱う必要があります。列のNullability(列がnullになりうるかどうか)は一部の実行計画に影響を与えます |
統計
| テーブルサイズ | カーディナリティー | 範囲の見積もり | |
|---|---|---|---|
| 概要 | テーブルの合計サイズの見積もりです | 少数のページ(デフォルト 20)をランダムでサンプルし、インデックスカラムの固有の値の数を推測します | オプティマイザがInnoDBに最小値と最大値を入力として問合せ、その範囲にある行数の見積もりを受け取ります |
| 適用対象 | 全カラム | インデックスカラム | インデックスカラム |
| 計算 | 事前 | 事前 | 利用するときに実施 |
| 自動更新 | 通常オペレーション3中 | テーブルの10%に変更が発生したとき | - |
| 手動更新 | ANALYZE TABLE |
ANALYZE TABLE |
- |
| 設定オプション | - | ページのサンプル数4 | 最大インデックスダイブ数5、最大メモリ利用量6 |
| 正確性 | 最も正確でない | データ分布の偏りに依存 | 最も正確 |
| 一般的な使われ方 | テーブルスキャンコストの決定に利用。インデックスがない場合の結合順に利用(大きいテーブルから先に) | 結合順の決定に利用。範囲の見積もりが最大インデックスダイブ数を超えた場合にも利用される | 述部の評価に利用。(利用可能なインデックスから何行マッチするかを推定)。population > 5000000がインデックスを使うべきでないかどうかを決めるのに利用する |
-
デフォルトの
optimizer_prune_levelは1です。この経験則を無効化し、全ての計画を評価するには値を0に設定してください。 http://dev.mysql.com/doc/refman/5.7/en/controlling-query-plan-evaluation.html をあわせて参照してください。 ↩ -
デフォルトの
optimizer_search_depthは64です。値を小さくすると見積もりにかかる時間は削減できますが、他方で計画の精度が悪くなる可能性が発生します。 ↩ -
統計は通常のオペレーション中に更新されますが、正確性は保証されません。 ↩
-
サンプルするページ数は
innodb_stats_persistent_sample_pagesで変更できます。値を大きくすると見積もりがより正確になります(見積もり生成コストはいくらか増えます) ↩ -
オプティマイザはINリストが
eq_range_index_dive_limit items(デフォルト 200)を超えた場合にカーディナリティー評価に切り替えます。 ↩ -
rangeオプティマイザは
range_optimizer_max_mem_sizeにサイズを制限しています(デフォルト 8M)。オプションを組み合わせた場合は内部で展開されるため、複数のINリストを利用するクエリーはこの値を超えます。 ↩